
通過深度學習技術提升立體深度估計
http://www.kblhh.cn 2025-09-08 16:25 來源:TELEDYNE
概述
立體深度估計在機器人技術、AR/VR和工業(yè)檢測中至關重要,它為諸如箱體拾取、自動導航和質(zhì)量控制等任務提供了精確的3D感知。Teledyne IIS的Bumblebee X立體相機既具備高精度,又能夠提供實時性能,能夠在1024×768分辨率下以38幀每秒(FPS)的速度生成詳細的視差圖。
Bumblebee X基于半全局塊匹配(SGBM)算法,在紋理豐富的場景中表現(xiàn)穩(wěn)定。然而,像許多傳統(tǒng)立體方法一樣,在低紋理或反射表面上,特別是沒有圖像投影儀的情況下,Bumblebee X可能會出現(xiàn)視差缺失或深度數(shù)據(jù)不完整的情況。
近期,深度學習(DL)技術的進展為提高視差精度、準確性和完整性提供了有力的解決方案。本文將通過實際測試,探討這些方法的優(yōu)勢、局限性,并分析它們在嵌入式系統(tǒng)中的適用性。
在評估這些方法之前,我們首先需要了解傳統(tǒng)立體技術所面臨的實際挑戰(zhàn)。
立體深度估計:挑戰(zhàn)與局限性
傳統(tǒng)的立體算法,如內(nèi)置SGBM,提供了快速高效的視差估計,非常適合嵌入式和實時應用。這些方法在表面紋理良好的場景中表現(xiàn)穩(wěn)定,不需要GPU加速或訓練數(shù)據(jù)。
然而,在更復雜的環(huán)境中,尤其是具有反射或低紋理表面的場景中,它們可能會生成不完整或不準確的深度圖。
以下的倉庫場景說明了這些挑戰(zhàn)。長且重復的貨架減少了視差線索,而光滑的環(huán)氧地板反射了周圍光線,頂燈的鏡面高光則引入了匹配錯誤。
場景左右兩側(cè)出現(xiàn)空白區(qū)域是因為SGBM算法的MinDisparity被設置為0,并結(jié)合256級視差范圍,導致系統(tǒng)無法測量超出可測深度窗口的物體,特別是距離大約1.6米以內(nèi)的物體。為了捕捉這些近場物體,用戶可以選擇增加最小視差值(Scan3D坐標偏移)或切換到四分之一分辨率模式。
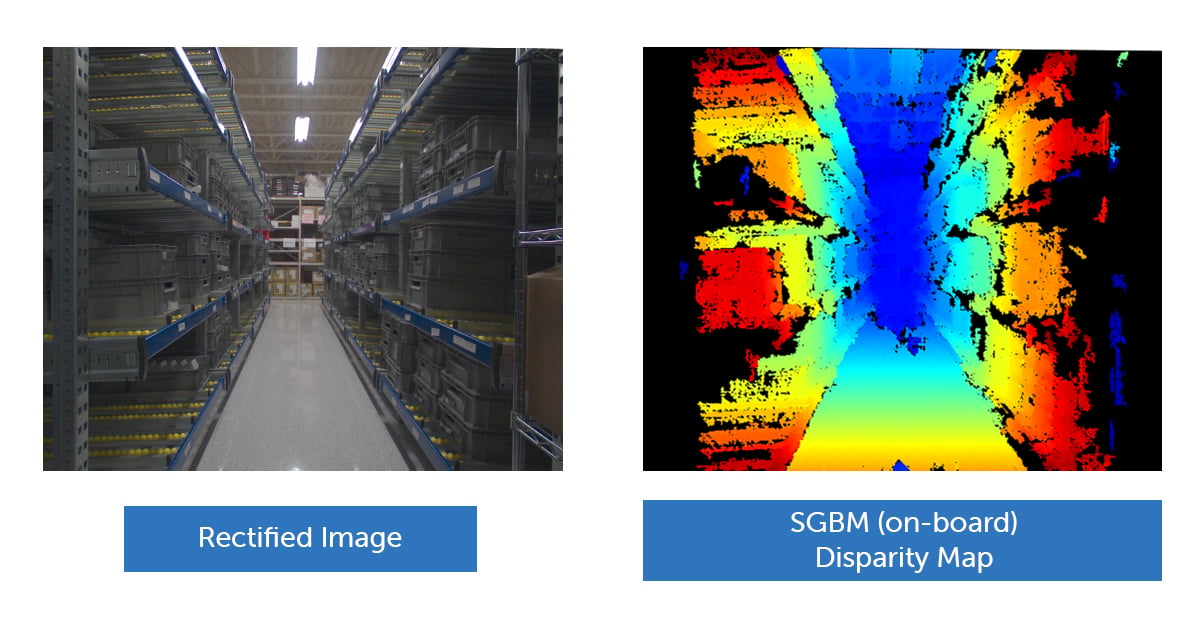
如以上視差圖像所示,SGBM在內(nèi)置視差引擎方面的缺陷十分明顯。
為了解決這些問題,在立體視覺應用中常用兩種互補的深度學習方法:
混合深度學習方法:
這種方法通過輕量化神經(jīng)網(wǎng)絡模型增強SGBM生成的初始視差圖。CVLAB-Unibo的神經(jīng)視差細化模型就是一個例子,通過利用空間和顏色線索來提高深度完整性,減少匹配偽影。作為一種混合方法,它在提高精度的同時保持了計算效率,特別適合實時或嵌入式系統(tǒng)。
端到端深度學習方法:
這種方法采用端到端的深度學習模型(如 Selective-Stereo 和 FoundationStereo),直接從立體圖像對中計算視差,而不依賴傳統(tǒng)的SGBM算法。這些網(wǎng)絡從大規(guī)模數(shù)據(jù)集中學習語義和上下文特征,使其即使在復雜的場景中(如遮擋或反射表面)也能生成密集、準確的視差圖。這一方法的缺點是對GPU要求較高,因此可能限制其在實時或資源受限環(huán)境中的使用。
接下來的章節(jié)將深入分析每種方法,評估它們在實際場景中的精度、運行表現(xiàn)和覆蓋效果。
混合深度學習方法(神經(jīng)視差細化模型)
方法描述
CVLAB-Unibo的神經(jīng)視差細化方法通過傳統(tǒng)方法(如SGBM)提升生成的現(xiàn)有視差圖質(zhì)量。該方法使用帶有VGG-13骨架的深度卷積神經(jīng)網(wǎng)絡(CNN),并采用U-Net架構(gòu),旨在:
根據(jù)空間和色彩一致性填補視差空白
通過學習的空間背景信息銳化邊緣
減少常見的立體匹配偽影,如條紋
網(wǎng)絡架構(gòu)
神經(jīng)細化網(wǎng)絡處理兩個輸入:
來自立體相機的左側(cè)RGB圖像
Bumblebee X生成的原始視差圖
U-Net架構(gòu)利用跳躍連接有效地將粗略的視差估計與來自RGB輸入的細節(jié)融合,顯著提高深度圖的完整性。
性能
NVIDIA RTX 3060 GPU上神經(jīng)視差細化的推理速度約為3FPS,適用于異步實時增強。
在同一個倉庫場景中,我們通過將從內(nèi)置視差引擎獲得的輸出與左側(cè)校正圖像一起輸入到神經(jīng)視差細化模型中,以優(yōu)化視差。結(jié)果如下所示:

從視差圖像中可以看出,應用該網(wǎng)絡后,倉庫場景中的空洞減少,地面匹配誤差也得到了修正。然而,由于細化依賴于SGBM的先驗數(shù)據(jù),在SGBM沒有數(shù)據(jù)的區(qū)域(如場景的左右邊緣),仍然可以觀察到一些空洞。
若要重現(xiàn)這些結(jié)果,請訪問GitHub上的深度學習示例。
端到端深度學習方法(Selective-Stereo)
方法描述
Selective-Stereo和Foundation-Stereo是兩種先進的深度學習框架,直接從立體圖像對計算視差圖,無需依賴傳統(tǒng)的匹配算法(如SGBM)。它們在架構(gòu)中采用了自適應頻率選擇,將高頻邊緣與低頻平滑區(qū)域區(qū)分開,從而優(yōu)化了不同區(qū)域的處理。
網(wǎng)絡架構(gòu)
Selective-Stereo基于IGEV-Stereo架構(gòu),并結(jié)合門控遞歸單元(GRU)進行迭代細化。該方法根據(jù)圖像頻率特征動態(tài)調(diào)整計算重點:
高頻分支增強邊緣和細節(jié)
低頻分支維持平滑區(qū)域輪廓并避免過擬合
性能
盡管這種方法具有高精度和完整性,但計算量大,基于NVIDIA RTX 3060 GPU的幀率約為0.5FPS。
基于以下所示結(jié)果,端到端深度學習方法提供了較為廣泛的視差覆蓋范圍,并且能保持精細的結(jié)構(gòu)細節(jié):例如,清晰渲染的天花板燈具,同時避免了由燈具反射引起的斑點偽影。
總體而言,完全端到端的視差估計網(wǎng)絡在視差覆蓋和結(jié)構(gòu)細節(jié)保留方面優(yōu)于原始內(nèi)置SGBM輸出和神經(jīng)細化系統(tǒng)流程,盡管其運行時間較長,且對更強大的GPU有一定要求。

若要重現(xiàn)這些結(jié)果,請訪問GitHub上的深度學習示例。
其他考慮因素
與內(nèi)置視差結(jié)果類似,距離小于1.6米的表面(超出0-256視差范圍)無法準確處理。右下角的儲物箱就展示了這一問題:由于它距離相機非常近,應該位于極紅范圍內(nèi),但網(wǎng)絡為其分配了較小的視差,導致其被置于比實際更遠的位置。這種局部誤差會破壞深度圖,在該區(qū)域生成不準確的點云。
某些深度學習模型提供了調(diào)整最小視差的選項,從而正確捕捉近距離物體,而其他模型則不支持此功能。如果所選的深度學習模型不允許調(diào)整最小視差,可以將右圖像向左平移所需的最小視差像素,再將該值加回每個輸出視差中。
另外,有些深度學習模型會限制其操作的視差范圍。在這種情況下,需要調(diào)整輸入的校正圖像大小,以適應相同的可測深度范圍,但這會犧牲一些深度精度。
許多深度學習模型還需要根據(jù)特定場景進行微調(diào)(盡管高級的“基礎”立體網(wǎng)絡可以實現(xiàn)零樣本泛化),而SGBM和基于SGBM的混合模型則無需任何調(diào)優(yōu),并能在各種場景中提供可靠的即用型性能。
比較實驗分析
我們使用已知距離為5米的隨機圖案進行了實驗基準測試。相機以1024×768分辨率(四分之一模式)運行。在精度測試中,定義了感興趣區(qū)域(ROI),確保它完全位于紋理清晰的圖案部分,只有明確定義的特征才會影響深度統(tǒng)計。覆蓋評估分為兩個階段:首先評估紋理區(qū)域,然后評估相鄰的無紋理光滑白色表面。下圖展示了所得到的視差圖。

測試結(jié)果包括:
|
|
有紋理區(qū)域的覆蓋率(%) |
無紋理區(qū)域的覆蓋率(%) |
中值深度(m) |
中值誤差(m) |
中值誤差(%) |
幀率(FPS) |
SGBM (板載) |
100.00 |
18.48 |
5.052 |
0.052 |
1.03 |
38 |
SGBM + 神經(jīng)網(wǎng)絡精化 (Neural Refinement) |
100.00 |
100.00 |
5.058 |
0.058 |
1.17 |
3 |
Selective-Stereo |
100.00 |
100.00 |
4.988 |
-0.012 |
-0.24 |
0.5 |
觀察結(jié)果:
神經(jīng)細化方法顯著提高了視差的完整性,略微增加了中間誤差。
Selective-Stereo提供了出色的完整性和較小的偏差,表明其在精度要求較高的應用中表現(xiàn)良好。
實際應用指南
針對特定應用場景的建議:
高速實時應用(≥30FPS):使用Bumblebee X內(nèi)置的SGBM算法,必要時結(jié)合圖案投影儀,以提高完整性。
平衡覆蓋與延遲:將神經(jīng)視差細化與內(nèi)置SGBM異步結(jié)合,增強覆蓋范圍。
出色精度與完整性:當?shù)蛶士山邮芮腋呔戎陵P重要時,選擇Selective-Stereo。
結(jié)論
深度學習方法在復雜環(huán)境中顯著提升了Bumblebee X內(nèi)置SGBM的表現(xiàn)。輕量級細化方法能夠在普通硬件上進行實時改善,而端到端網(wǎng)絡則在速度要求較低時提供更高的質(zhì)量。與許多受限于固定系統(tǒng)流暢或缺乏內(nèi)置處理的立體相機不同,Bumblebee X同時支持這兩種方法,賦予用戶在精度、速度和計算能力之間優(yōu)化的靈活性,適用于各種應用場景。
相關新聞
- ? 為運動注入智能:結(jié)合 AI、立體視覺與邊緣計算
- ? Teledyne推出 Z-Trak Express 1K5,實現(xiàn)經(jīng)濟高效的在線3D測量和檢測
- ? Teledyne Space Imaging 發(fā)布通過航天級篩選的工業(yè)圖像傳感器
- ? 如何通過智能軟件和硬件解決方案克服實時立體視覺中的挑戰(zhàn)
- ? Teledyne的新款2.5 GigE Vision線掃相機,為用戶提供高性能、高性價比解決方案
- ? Teledyne e2v推出新型高速傳感器,拓展近紅外波長下的靈敏度
- ? Teledyne推出用于在線3D測量和檢測的Z-Trak 3D Apps Studio軟件工具
- ? Teledyne將于Vision China 2024 (上海)展示最新成像解決方案
- ? Teledyne FLIR IIS擴展其Forge相機系列,達到IP67防護等級,適用于智能農(nóng)業(yè)、食品和飲料行業(yè)
- ? Teledyne FLIR IIS擴展其Forge相機系列,達到IP67防護等級,適用于智能農(nóng)業(yè)、食品和飲料行業(yè)
編輯精選
- ? 東土科技連投三家核心企業(yè) 發(fā)力具身機器人領域
- ? 第七屆工業(yè)互聯(lián)網(wǎng)大賽在京正式啟動
- ? 珞石機器人沖刺港交所主板上市
- ? 9月RatingDog中國制造業(yè)PMI升至51.2,延續(xù)擴張態(tài)勢
- ? ABB與軟銀簽約擬出售機器人業(yè)務
- ? 全球工廠機器人需求十年翻番——國際機器人聯(lián)合會發(fā)布《2025年世界機器人報告》
- ? 2025年度綠色工廠推薦工作啟動
- ? 羅克韋爾自動化重磅推出 ControlLogix 5590 控制器,引領工控新時代
- ? 華為系公司賽力斯與字節(jié)合作具身智能,問界要開發(fā)人形機器人?
- ? 40.5萬億元工業(yè)增加值 工業(yè)家底更厚實
工控原創(chuàng)
- ? 十月工控領域重要資訊,一睹為快!
- ? 回顧 | 以技術干貨 + 落地案例,解鎖產(chǎn)業(yè)升級新路徑
- ? ABB報告:工業(yè)停機每小時損失高達50萬美元,知行鴻溝阻礙現(xiàn)代化更新
- ? ABB宣布以53.75億美元將機器人業(yè)務出售給軟銀
- ? 九月不容錯過的工控圈大事
- ? 當“軟件定義”與“價值鏈”相遇,未來工業(yè)走向何方?
- ? 西門子:以“一次正確”破局內(nèi)卷,讓工業(yè)AI真正落地
- ? “四大家族”“四小龍”齊聚,工博會機器人展的亮點都在這了!
- ? 2025工博會開幕,工業(yè)AI釋放創(chuàng)新潛力
- ? 繁易的戰(zhàn)略進擊:從HMI到PLC,走向全棧式自動化融合創(chuàng)新


