ģ�M����|��ȌW��|GAN|���\��
AI̓�M��|���W��|�D���D�Q|�ԱO���W��
�S��ģ�M���桢�˹����ܡ���ȌW���Ŀ��ٰlչ��GAN���g��Ó�f�����o�D�W�j�İlչ�����˾��ϡ�
���W������A�����Ǽٵģ�
2022
�M�M�ĺڿƼ����^���DZ��ö��W����һ�����c��
�oՓ���@�G���_Ļʽ��߀�Lj��^����Ľ��O���o�����Ƽ���һ�δ�����ݛՓ���@�@��
Ȼ�����f�f�]�뵽���ǣ����B�o�x�ֺ��^������⌍�r����ȻҲ�_����һ���µĸ߶�:
�����@���DƬ������ܕ��룬�@���ǡ��Ї���⡷���������T��
����������ˡ�
�D�����鲢ï�������ģ������������ˣ�����һ�������AI̓�M��——�TС�⡣
��ô�TС�������ӟ��ɵ��أ�
��Ч���Ͽ������@������������T��������Ӗ��Ŀ�ˡ�
�TС�ⱳ���“�����”�ǔ��\��̓�M�˼��g��
��֮�����ܷ����沿�����顢֫�w���������w��Ȼ�Ⱥͱ�������y�棬��Ҫ�Y��GAN������W�j��Ⱦ���g��
����Ӗ������ֻ��һ�ܡ�
ֵ��һ����ǣ����Z��ģ�͡���͌���ģ�ͺ���Ę��Ⱦ����ģ�͵�Ӗ���£�“�TС��”�ʴ_�،W���T����첿�������۲����沿����֮�g�ąf�{�ԡ�
�������W�����g���TС�⌢�^�m����“���W�����^ِ����ָ��“�����w�����^ِ�����w���ܺͽ�����ʾ�������w�к���ָ��������ָ������ðָ��������ָ��������ָ�����oĿ�Rָ���Ț���ָ�ˣ����^ِ��Ⱥ���r���f������^����������ָ��������Ϣ���鹫����������ȫ�^ِ�ṩ����l������������
GAN���ɈD��C��
2022
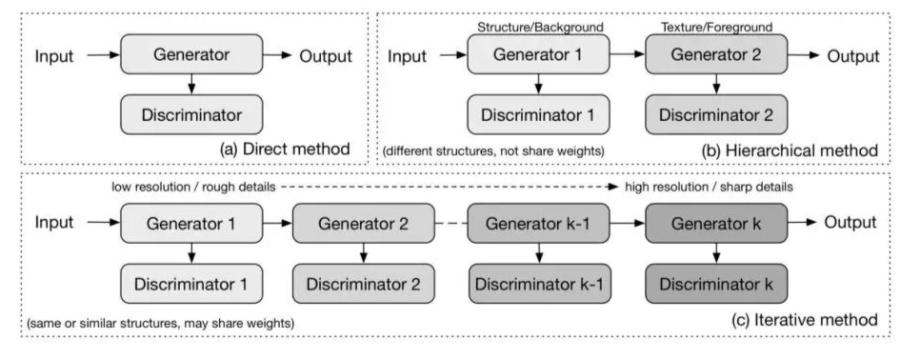
������ͬGAN�����е����������Єe���Ĕ��������Ԍ�GAN�D�����ɵķ������������ֱ�ӷ��������������ͷӷ�����
GAN�ڈD�������е������
ֱ�ӷ�
����GANs����ѭ��ģ����ʹ��һ����������һ���Єe����ԭ�����������������Єe���ĽY����ֱ�ӵģ��]�з�֧����GAN ��DCGAN ��ImprovedGAN��InfoGAN ��f-GAN ��GANINT-CLS ���@������OӋ�͌��F�ϱ��^���ף�ͨ��Ҳ�ܵõ����õ�Ч����
�ӷ�
�ӷ�����Ҫ˼���nj��D��ֳɃɲ��֣���“��ʽ�ͽY��”��“ǰ���ͱ���”������ģ����ʹ�Ãɂ��������̓ɂ��b�e�������в�ͬ�����������ɈD��IJ�ͬ���֣�Ȼ���ٽY���������ɂ�������֮�g���Pϵ�����Dz�����
��SS-GAN��������ʹ�Ãɂ�GAN��һ��Structure-GAN�������ɱ���Y����Ȼ������Style-GAN�a��DƬ������������ɈDƬ�����w�Y��������ʾ��
SS-GAN�ķӽY��
������
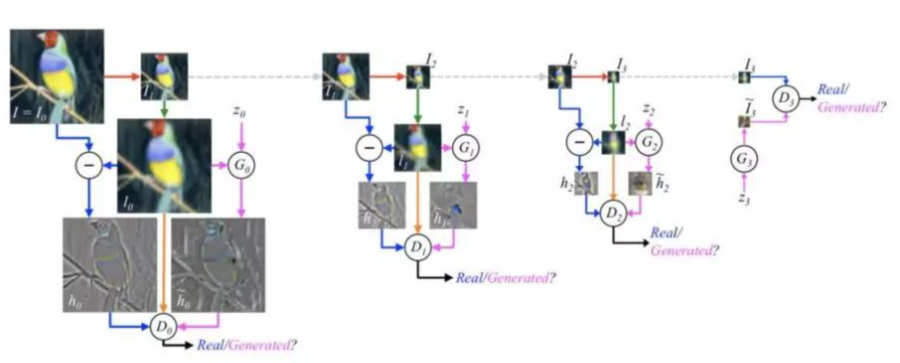
������ʹ�þ�������������ͬ�Y���Ķ��������������^�������ɏĴֵ����ĈD��
��LAPGAN������LAPGAN�еĶ���������������ͬ���΄գ���ͼ��e���������H������������ݔ�벢ݔ���D����������������ǰһ���������@ȡ�D����ʸ������ݔ�룬�@Щ�������Y����Ψһ�^�e����ݔ��/ݔ���ߴ�Ĵ�С��ÿһ�ε�����ĈD���и��������ļ�����
LAPGAN�ĵ����Y��
GAN-�D���D�Q
2022
�D�D����D�Q�����x�錢һ�������Ŀ��ܱ�ʾ�D�Q����һ�������Ć��}������D��Y���Dӳ�䵽RGB�D���߷��^����ԓ���}�c�L���w�����P������Ã��݈D��͘�ʽ�D��ݔ�����Ѓ��݈D��ă��ݺ͘�ʽ�D��Ę�ʽ�ĈD�D�D���D�Q���Ա�ҕ���L���w�Ƶĸ�������������H�����D�ƈD����L��߀���Բٿv����Č��ԡ�
�D�D����D�Q�ɷ֞��бO���͟o�O���ɴ���������ɽY���Ķ������ֿɷ֞�һ��һ���ɺ�һ�������Ƀ��
�бO���D�D���D�Q
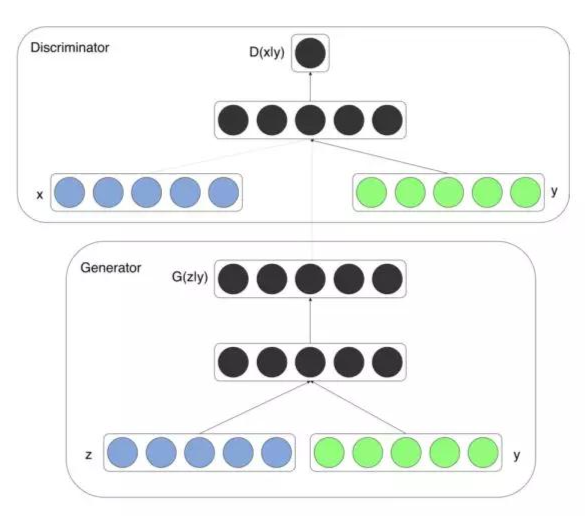
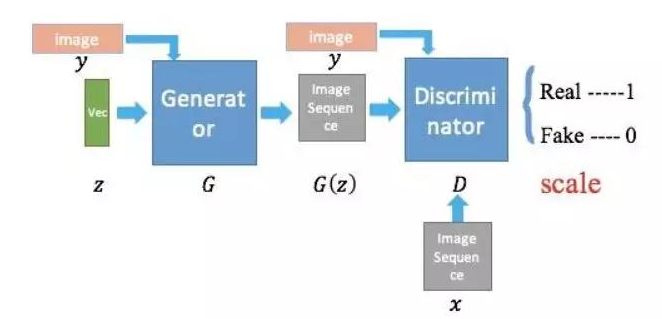
��ԭʼGAN�У����ݔ���H��ه���S�C�������ԟo���������ɵă��ݡ���cGAN�����ʹ���҂����Ԍ��l��ݔ��y���ӵ��S�C��z���Ա����ɵĈD����G(z,y)���x���l��y�������κ���Ϣ����D���ע������Č��ԡ��ı������������LjDƬ��
CGAN�ĽY��
�������DƬ����O����Ϣ��cGAN�Ϳ������һЩpaired data������ɵ��΄գ����݆���D�D�����挍�DƬ����mask�D�����挍�D���ѺڰD�D�����挍�D�ȡ�������ߴ����ԵĹ�����pix2pix��
pix2pix�Y���D
�o�O���D�D���D�Q
�mȻ�бO���D���D�Q���Եõ��ܺõ�Ч��������Ҫ�ėl����Ϣ�Լ�paired image�ɞ���ܴ�����ơ�������ßo�O���W�����W�����ľW�j���ܕ�����ͬ��ݔ��ӳ��ɲ�ͬ��ݔ�����@����ζ�����҂�ݔ������xi�����ܵõ���Ҫ��ݔ��yi��
CycleGAN ��DualGAN ��DiscoGANͻ�����@�����ƣ��@��헹����������һ��/�ؘ��pʧ��consistent loss������ȡ��һ��ֱ�^��˼�룺�����ɵĈD��������ӳ�����ɻ�ȥ��ԓ�cݔ��ĈD��M���ܽӽ������D�Q��ʹ�Ãɂ��������̓ɂ��Єe�����ɂ��������M���෴���D�Q��ԇ�D���D�Q���ں���ݔ��D��
��CycleGAN��������CycleGAN�У��Ѓɂ���������Gxy���ڌ��D�����X��ݔ��Y��Gxy���ڈ����෴���D�Q�����⣬߀�Ѓɂ��Єe��Dx��Dy�Д��D���Ƿ����ԓ��
CycleGAN��������
һ��һ���ɵ�һ��������
��pix2pix��CycleGANϵ�У��ٵ�UNIT���@Щ�������F��image-to-image translation�������бO����߀�ǟo�O���ģ�����һ��һ�ģ�Ҳ�����fݔ��һ���DƬֻ�ܮa��һ�N�L��ȱ�������ԡ����䌍�������r�£�image translation�Ƕ�����ģ�Ҳ����һ���DƬ������ͬ�L����D�Q�DƬ�������҂��OӋ�·��r��һ��݆���D�䌍�����OӋ�ɲ�ͬ�L����·����ٱ���ͬһ����������ͬ�Ĺ��l������һ��ģʽ����һ��ֻ�а���ͺ�ҹ��߀�����а����峿�ȡ�
BicycleGAN���Ȍ����M���ˇLԇ������ģ���������S�C����ͨ�^�S�C�ɘ�ʹ���õ���ͬ�ı��_������ݔ���c���ڿ��g�������p��ӳ�䡣�p��ӳ��ָ���ǣ����H�����ɝ��ھ��aӳ��õ�ݔ��Ҳ������ݔ�����^�����Ɍ����ĝ��ھ��a���@���Է�ֹ�ɂ���ͬ�ĝ��ھ��a����ͬ�ӵ�ݔ��������ݔ���Ć�һ�ԡ�
��ֱ���ò�ͬ���S�C�����a�����ӻ��ĽY��������mode collapse�Ĵ��ڣ�������Ӗ��ʧ����MUNIT��DRITUNIT�Ļ��A�ϣ���latent code�Mһ����������ݾ��a C���L�a S����ͬdomain�ĈD������ݾ��a���g C �������L�a���g S �������ݾ��aC�c��ͬ���L�aS�Y���������ܵõ������Ķ����ԵĽY����
MUNIT��latent code�֞����c���L��c
������ʾ��BicycleGAN��MUNIT��DRIT��ȡ���˲��e�����ɽY����
GANģ�ͷ���
2022
�����Բ�
�����Բ�ָ����GAN��Ӗ�����^���к��y���պ��ݶ���ʧ���ݶ��e�`֮�g��ƽ�⡣�҂��ȿ�����ʲô�����F�ݶ���ʧ�Ć��}�����Pע�Єe�W�j���� �� ��֪����ʽ��2���Č������㣬�ɽ������Єe�飺
������뵽ʽ��7���ɵã�
���� ��
Ҳ�����f�����Єe�W�j��ĕr�����ɾW�j��Ŀ������С���ֲ� �� ֮�g�� ɢ�ȡ����ɂ��ֲ���ͬ�r ɢ�Ȟ��㣬�����ɾW�j���ֵ �����ēpʧ�� ��
Ȼ�����H��r�ǣ������T���ݶ��½��ȷ�ʽȥ��С��Ŀ�˺��� �ĕr�����ɾW�j��Ŀ�˺����P�څ������ݶȞ��㣬�o�����¡���ʲô�����F�@�N��r�أ�ԭ���� ɢ�ȱ��������ԣ����ɂ��ֲ��]���دB�ĕr������֮�g�� ɢ�Ⱥ�� �����װl�F�˕rĿ�˺�����0����ζ����Єe�����Єeȫ�����_�����������ɔ�����ݔ������0����ˌ�Ŀ�˅������Ԟ�0���������ݶ���ʧ���y�}��
����ڌ��H�У��҂����������Єe�W�jӖ�������ֻ�M�� ���ݶ��½����Ա��C���ɾW�j���ݶ���Ȼ���ڡ�����������Ӗ���Δ�̫�ٌ����Єe�W�j�Єe����̫��t���ɾW�j���ݶȞ��e�`���ݶȡ���δ_�� �@����������ƽ����ݶ���ʧ���ݶ��e�`֮�g��ƽ���ǂ��y�}���@Ҳ�Ǟ�ʲô�fGAN��Ӗ���r�����Բ��ԭ��
ģ��̮��
���˷����ԲGAN��Ӗ���ĕr��߀���׳��Fģ��̮���Ć��}��ģ��̮��ָ���ɾW�j�A�������ɸ�“��ȫ”�Ęӱ��������ɔ����ķֲ��ۼ���ԭʼ�����ֲ��ľֲ��������҂�������ʲô�����F�@�����}��
����Єe�W�j ����ʽ��4�����õ����ɾW�j��Ŀ�˺����飺
�˕r�� ������ �����н纯����������ɾW�j���ֵ����������KLɢ�� ��Ӱ푡�
ʲô��ǰ�������KLɢ�ȣ���������Ŀ���M�Ѓ���������ʲô�Y�����҂��ȿ�����һ�����}��
KLɢ����һ�N�nj��Q��ɢ�ȣ���Ӌ���挍�ֲ� �����ɷֲ� ֮�g��KLɢ�ȵĕr�������ͬ���֞�ǰ��KLɢ�Ⱥ�����KLɢ�ȣ�
��ǰ��KLɢ���У�
�� �� �r�� ����ζ�� �ĕr�� �oՓ��ôȡֵ�����ԣ���������ǰ��KLɢ�ȵ�Ӌ��a��Ӱ푣���˔M�ϵĕr���ûر� ���c��
�� �� �r�� ����ζ��Ҫ�pСǰ��KLɢ�ȣ� ��횱M���ܸ��w ���c��
��ˣ�����ǰ��KLɢ�Ȟ�Ŀ�˺����M�Ѓ����ĕr��ģ�ͷֲ� ���M���ܸ��w�����挍�ֲ� ���c�������ûر� ���c��
������KLɢ���У�
�� �� �r�� ����ζ��Ҫ�pС����KLɢ�ȣ� ��횻ر����� ���c��
�� �r���oՓ ȡʲôֵ�� ����ζ�� ����Ҫ���]���]�Ƿ���Ҫ�M���ܸ��w�����挍�ֲ� ���c��
��ˣ���������KLɢ�Ȟ�Ŀ�˺����M�Ѓ����ĕr��ģ�ͷֲ� ���M���ܱ��_�����挍�ֲ� ���c��������Ҫ���]�Ƿ��w�����挍�ֲ� ���c��
�D�o���ˮ��挍�ֲ����˹��Ϸֲ���ģ�ͷֲ���θ�˹�ֲ��ĕr����ǰ��KLɢ�Ⱥ�����KLɢ���M��ģ�̓����ĽY�������l�Fʹ������KLɢ���M�Ѓ���������ģ��̮�s�Ć��}��
��ˣ����������ɂ����}��GAN�yӖ���Ć��}�dz������ġ����˽�Q�@Щ���}�����m����������˸�ʽ���ӵ�GAN������W-GAN��ͨ�^��Wasserstein���x����JSɢ�ȣ�������GAN�����Բ�Ć��}��ͬ�rһ���̶��Ͼ�����ģ��̮�s�Ć��}��
GAN��ԭ������Ԋ��̩�ꠖ
2022
��������ǰ�ĺڰ�Ӱ��������ɫ�ʣ����Ěvʷ���x��������һ���أ�
���գ�һ��̩�ꠖ1930�����v���FӰ��AI�ޏ�߀ԭ��
��ô���\����ʲô���g��̩�ꠖӰ��߀ԭ���أ�
RIFE��Deep-Exemplar-based-Video-Colorization��GPEN��һϵ���˹������Ŀ��̩�ꠖӰ���߀ԭ�����˾�ؕ�I��
����RIFE��һ�����rҕ�l�厬�������܌��F���fӰ�ߎ��ʵ�����
���⣬�ڴ���һ���a���Ŀ��DAIN��
Deep-Exemplar-based-Video-Colorization�ǁ���һ�N�Y���ˈD��z���c�D����ɫ��ģ�͡�ԓģ�����ȕ��Ĵ������ՈD���Йz���ͻҶȈD���ƵĈD��Ȼ���ٌ�ԓ���ՈD�����ɫ�����w�Ƶ��ҶȈD�У����F�˷dz��õ���ɫЧ����
GPEN��GAN prior embedded network��GAN���Ƕ��W�j�����x�_Դ�Ŀ���ɇ��˴��죬����������߀ԭЧ�������ɫ��
�Y����������Ч�����@���������M�ć��ؓp�ĵ���Ę�D���ԭ��Blind face restoration��������
߀��DeOldify��DeOldify ʹ����NoGAN �M��Ӗ����NoGAN���ګ@�÷������S����ʵĈD�������P��Ҫ�ġ�
NoGAN Ӗ���Y���� GAN (�������ɫ)�ĺ�̎��ͬ�r�����˸�����(��ҕ�l���W�q����)��
���������@Щ�_Դ��AIģ�ͣ�߀�Y���˸߳��ĺ��ڼ��ɣ�����ǰ���ϱ�������Ϻ��r�b��������������س��F���˂���ǰ��
�{�����XҺ��GPU����վ���ɴ�� NVIDIA 4 × A100 / 3090 / P6000 / RTX6000��ʹ�� NVLink + NVSwitch�����GPUͨ�ţ�4������ GPU Direct RDMA��NIC��1��1 GPU���ʣ������4 x NVMe����GPUϵ�y�P������ AIOM�p�Դ����ϵ�y�����ד�������ӿ���o�����ṩ GPU �����ĸ�����Ӌ�㣬��������ȌW�����ƌWӋ�㡢�D�ο�ҕ����ҕ�l̎����N���È������{�����XҺ��GPU����վ��GAN���g�İlչ�ṩӲ�����ϡ�