
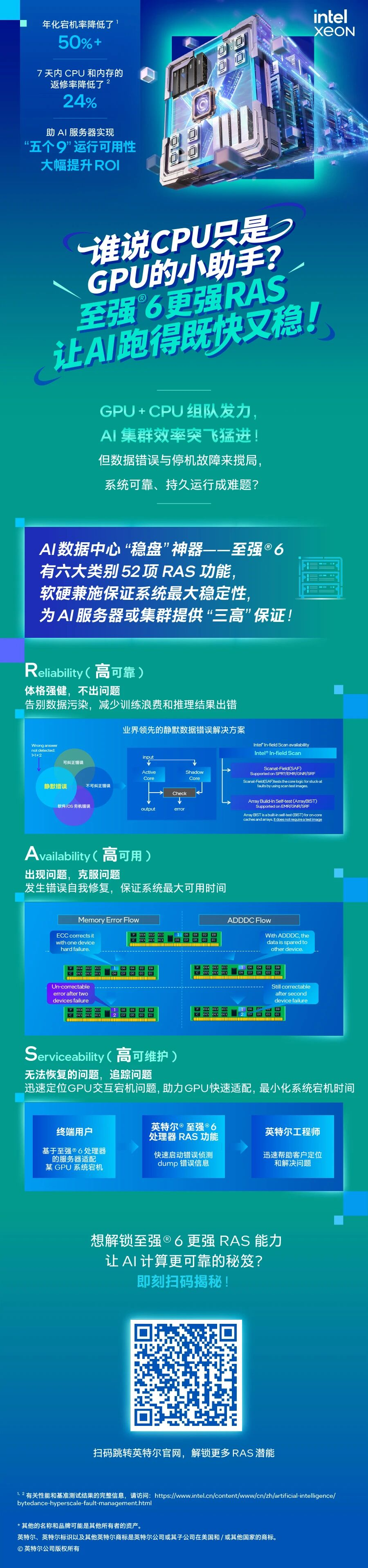
AI平臺只求快=白燒錢 選至強做機頭“穩”住超大集群
http://www.kblhh.cn 2025-12-30 11:32 來源:英特爾

過去做企業級IT,如今搞企業級AI,都有點像跑船打漁,船越大就越不能只圖快,更得求穩,否則船一翻,載得漁獲越多損失就越重。確實是風浪越大魚越貴,前提是你得平安返港。
再具象點說,你可能聽過這樣的數據:超40%的大中型企業每小時停機成本超過100萬美元,甚至超過500萬美元,這不是聳人聽聞,是來自實際統計。在“算力即財富”的AI時代,服務器宕機帶來的損失,比直接燒錢來得還快!而且這種情況出現的可能性還挺高,畢竟AI集群正加速向萬卡級規模突破,系統越復雜、計算密度越高,就越可能出現更多的靜默數據錯誤(SDE)及發生在內存與PCIe等組件中的故障。
別等問題發生時我們才警覺:不能只將目光聚焦在GPU或各種AI加速器的算力能否充分發揮上。沒有一個穩定可靠的運行環境,這種發揮就不能持久,而不持久比不充分更虧本兒。
誰能從根本上解決這個問題?指望加速器芯片不現實,畢竟它們的任務是計算,需要依賴主控(或機頭)系統才能進行工作,你要依賴的,恰恰是一直在AI服務器或集群中被視為“配角“的CPU。如果你選擇至強®6 處理器作為機頭或主控,它的“三高”能力(高可靠性、高可用性、高可維護性,RAS)就能接過保障整體系統穩定運行的重任,為GPU創造一個“心無旁騖”、“全力輸出”的環境,實現整個系統1+1>2的效能倍增。
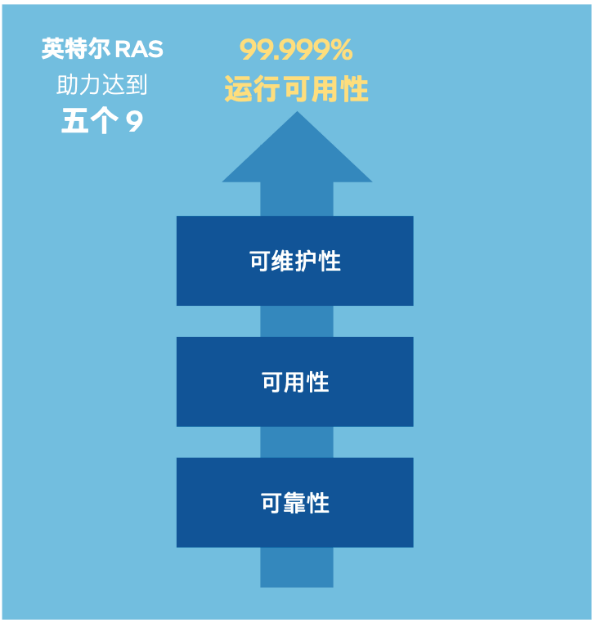
或許你會說,各家企業級CPU都有RAS特性或功能啊,為啥如此強調至強®6?這是因為它有一些獨具且強化的功能,能幫你的AI平臺與應用更好地避坑:
告別“數據污染”,為GPU掃清“靜默錯誤雷區”
在動輒千卡萬卡的AI集群中,一些微小的靜默數據錯誤就像潛伏的“地雷”,平時難以察覺,一旦“引爆”就可能污染訓練結果、干擾模型收斂,以及導致錯誤的推理結果。
擔當機頭或主控系統核心的至強®6,能主動扮演“排雷兵”的角色。它的絕技是利用硬件故障壓測與復檢工具套件 (SHC & DCDiag),鎖步模式 (Lock Step Mode) 和故障掃描巡檢(In-Field-Scan)等SDE檢出功能,對GPU前行的“道路“進行細致排查,提前揪出并排除這些“隱形錯誤”。這確保了機頭或主控CPU交付給GPU的計算任務是更為純凈或可靠的,能讓GPU的每一次運算都建立在更堅實可信的基礎之上。
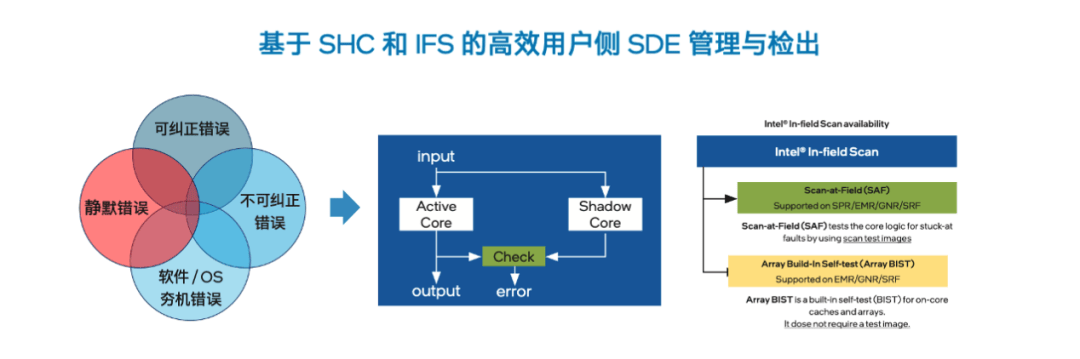
終結“頻繁宕機”:用更強可用性給GPU穩定工作上保險
可用性是AI集群“持久連續運行”的關鍵,至強®6在這方面承襲了英特爾在至強產品線上長達6代的技術迭代,積累了不少絕活兒,如:
1、內存糾錯與排障:通過SDDC、ADDDC等技術,能100%糾正單顆粒內存錯誤,并自適應修正多顆粒錯誤,為GPU提供穩定的數據通路。
2、服務容錯:MCA Recovery機制確保服務器在遇到非致命錯誤時可以“帶病運行”,避免GPU工作流無故中斷,到至強®6這一代,MCA Recovery還實現了更多恢復手段。
3、PCIe穩健器:eDPC功能保障了GPU與系統之間高速數據鏈路的穩定,這對于依賴海量數據交換的AI任務至關重要。

“首席技術支持” 為AI集群 構建分鐘級故障診斷與恢復體系
作為AI集群7 x 24小時待命的“首席技術支持”,至強®6 處理器配備RAS Offload與增強的內存故障EDAC driver,用來豐富故障上報信息,同時規避業務中斷影響與性能抖動。
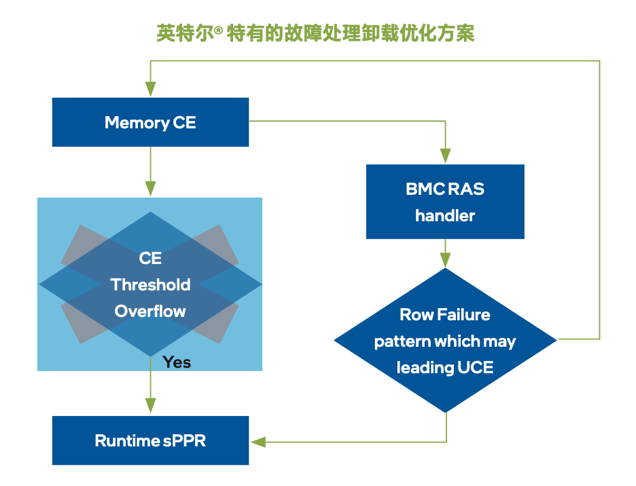
ACD、ASD等高級診斷工具,能將故障診斷的SLA(服務等級協議)從“周”級壓縮到“分鐘”級。

更重要的是,作為AI集群“壓艙石”,至強®6能通過上述工具鏈快速適配不同品牌GPU或AI加速器,輔助診斷、迅速定位并協助解決它們的故障,最大程度縮短整個系統的中斷時間,讓它們能“物盡其用”。
至強®6這“三高“能力疊加起來,就構成了目前AI服務器/集群機頭或主控領域獨一份的控場穩盤能力。有國內某頭部AI大廠的實踐證明,通過綜合應用至強這些RAS能力,CPU造成的宕機率已被降低了50%,二次返修率也顯著下降,讓其服務器的投資有了更優的回報。
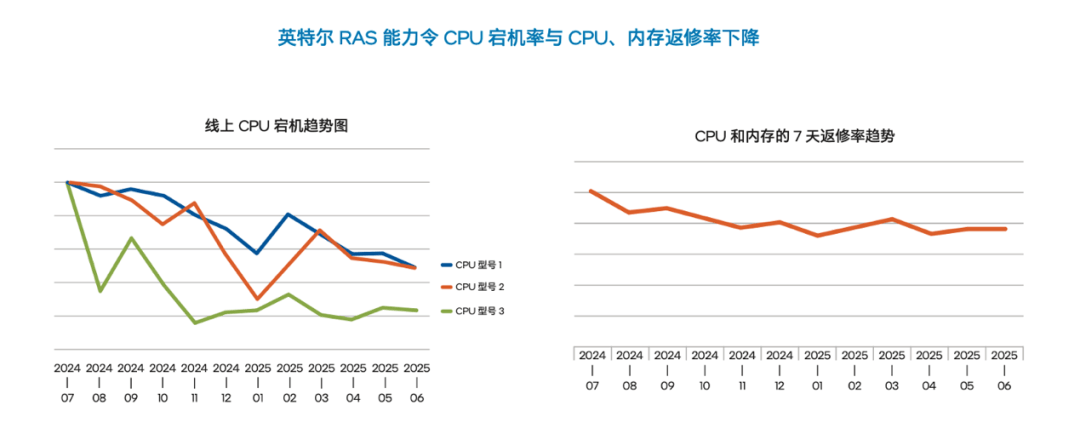
最后說個讓你意想不到的數字——至強®6平臺,目前在RAS具體特性或功能上,已集成了多達六大類52項細分功能,這些功能可能遠不如表面“可見”的CPU核心數、主頻、內存帶寬、互連通道等與性能密切相關的規格那樣醒目或振奮人心,但一旦遇到麻煩,你就會覺得它們還是多多易善、越強越好。這情形就像大船上的水密隔艙,平時用不上看不到以為是累贅,等撞上礁石,它們帶給你的,是帶傷也可繼續工作并能平安返港回家的從容。
編輯精選


